先頃、AmazonはAWS GlueがストリーミングETLをサポートすることを発表した。この新しい機能を使用すると、ストリーミングデータをオンザフライで準備し、数秒で分析できるようにする継続的取り込みパイプラインを簡単に設定できる。
AWS Glueは、フルマネージドの抽出、変換、および読込み (ETL) サービスであり、顧客が分析用にデータを簡単に準備および読込みできるようにする。Amazonは一般公開以降、いくつかの機能でサービスを更新した。最新の機能はストリーミングETLジョブのサポートである。Amazon Web Servicesのチーフエバンジェリスト (EMEA) であるDanilo Poccia氏は、新機能についてブログ記事に書いている:
継続的な取り込みパイプラインの管理とオンザフライでのデータ処理は、管理、パッチ適用、スケーリング、一般的な対応が必要な常時稼働システムであるため、非常に複雑です。今日、Apache Sparkに基づいて、Amazon Kinesis Data StreamsやApache Kafka (フルマネージドのAmazon MSKを含む)のようなストリーミングプラットフォームのデータを使って継続的に実行するように、AWS Glueジョブを拡張し、より簡単に、より費用対効果の高い方法で実装できます。
さらに、顧客は、Amazon S3のデータレイク、およびAmazon Redshiftなどのデータウェアハウスや他のデータストアにデータを取り込むために必要なインフラストラクチャをプロビジョニング、管理、およびスケーリングできる。次に、ETL、Amazon Athena、Amazon EMR、Amazon Redshift Spectrumなどのサービスを使用したクエリとレポートに使用できるGlue Data Catalogを介して、データの統合ビューを作成できる。
AWS Glueのユースケースは、顧客がジョブを使用してIoTイベントストリーム、クリックストリーム、ネットワークログなどのイベントデータを処理することである。Glueジョブでストリーミングデータを処理する場合、集計、パーティション化、フォーマットなどのデータ変換が実装ができるようするSpark Structured Streamingのすべての機能にアクセスできる。さらに、このデータを他のデータセットと結合して、分析を容易にするためにデータを強化またはクレンジングできる。
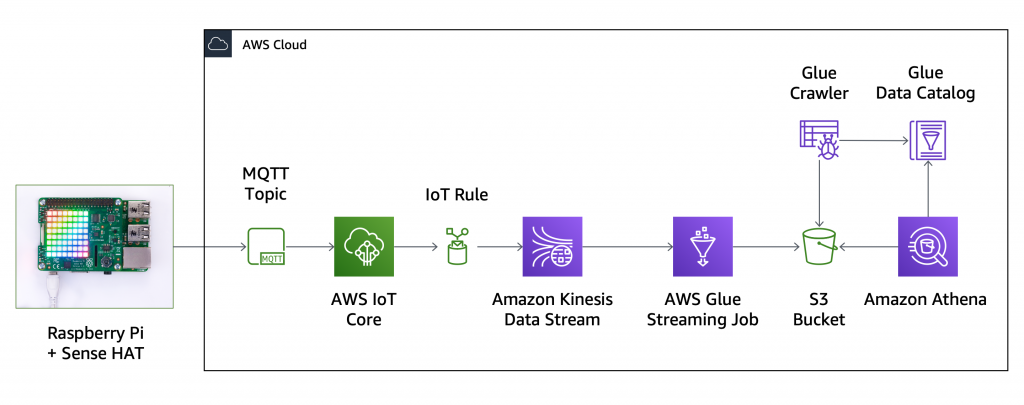
出典: https://aws.amazon.com/blogs/aws/new-serverless-streaming-etl-with-aws-glue/
AWS Glueは、ユーザが慣れ親しんだツールを使用してさらにカスタマイズできるストリーミングETLジョブのScalaまたはPythonコードを自動的に生成する。さらに、AWS Glueは構成および管理するコンピューティングリソースがない、サーバレスである。Poccia氏が同じブログ投稿で述べている:
Glueを使用してサーバレスETLパイプラインを管理すると、ストリーミングの取り込みプロセスの設定と管理が簡単かつコスト効率が高くなり、実装の労力が減るため、分析のビジネス結果に集中できます。
ストリーミングETL機能はAWS Glueと同じAWSリージョンで利用可能である。また、AWS Glueの価格の詳細は価格ページで確認できる。
"であるために" - Google ニュース
August 21, 2020 at 01:59PM
https://ift.tt/2Eb9A12
AmazonがAWS Glueに新しいストリーミングETL機能を導入 - InfoQ Japan
"であるために" - Google ニュース
https://ift.tt/2HbtK9j
Shoes Man Tutorial
Pos News Update
Meme Update
Korean Entertainment News
Japan News Update
No comments:
Post a Comment