この記事は “ Unified data preparation and model training with Amazon SageMaker Data Wrangler and Amazon SageMaker Autopilot ” を翻訳したものです。
データは機械学習 (ML) の原動力であり、データの質は ML モデルの品質に直接影響します。したがって、データの品質を向上させ、適切な特徴量エンジニアリング技術を採用することは、正確な ML モデルを作成するために非常に重要です。機械学習の専門家は、実世界のデータでうまく汎化され、望ましい結果をもたらす最適なモデルを作成するため、特徴量エンジニアリング、アルゴリズムの選択、その他の ML の側面を退屈に繰り返していることがよくあります。しかし、ビジネスのスピードは比例しないため、この非常に退屈で反復的なプロセスは、プロジェクトの遅延やビジネス機会の喪失につながる可能性があります。
Amazon SageMaker Data Wrangler は ML 用のデータの集計と準備にかかる時間を数週間から数分に短縮し、Amazon SageMaker Autopilot は、データに基づいて最適な ML モデルを自動的に構築、トレーニング、チューニングを行います。Autopilot では、データおよびモデルの完全な制御と可視性を維持できます。どちらのサービスも ML に携わる人々の生産性を向上させ、価値創造までの時間を短縮することを目的として作られています。
Data Wrangler は、データを準備し Autopilot で ML モデルをシームレスに学習させることができる統合的な体験を提供するようになりました。この新機能により Data Wrangler のユーザーインターフェース (UI) からデータを準備し、直接 Autopilot の実験を簡単に開始できるようになりました。わずか数クリックで、ML モデルの構築、学習、チューニングを自動的に行うことができ、最先端の特徴量エンジニアリング技術の採用、高品質な ML モデルの学習、データからのインサイト取得をより簡単に行うことができるようになります。
この記事では、Data Wrangler に新しく統合されたエクスペリエンスを使用して、データセットを分析し、Autopilot で高品質の ML モデルを簡単に構築する方法について説明します。
データセットの概要
Pima Indians はメキシコと米国アリゾナ州に住む先住民族です。研究により、ピマ・インディアンは糖尿病の高リスク集団であることが示されています。糖尿病のような慢性疾患に対する個人のリスクとかかりやすさの確率を予測することは、しばしば過小評価される少数民族の健康と幸福を改善するための重要な課題となっています。
本ブログでは Pima Indian Diabetes public dataset を使って、個人の糖尿病へのかかりやすさを予測します。Data Wrangler と Autopilot の新しい統合により 1 行のコードも書かずにデータを準備し、自動的に ML モデルを作成することに焦点を当てます
データセットには 21 歳以上の Pima Indian 女性に関する情報が含まれており、いくつかの医学的な説明 (独立) 変数と 1 つの目的 (従属) 変数である Outcome が含まれています。次の図は、データセットのカラムを説明するものです。
| 列名 | 説明 |
| Pregnancies | 妊娠回数 |
| Glucose | 2 時間以内の経口ブドウ糖負荷試験における血漿グルコース濃度 |
| BloodPressure | 拡張期血圧 (mm Hg) |
| SkinThickness | 上腕三頭筋皮膚襞厚 (mm) |
| Insulin | 2時間後血清インスリン (mu U/ml) |
| BMI | 肥満度 (体重 kg / 身長 m )^2 |
| DiabetesPedigree | 糖尿病血統機能 |
| Age | 年齢 |
| Outcome | 目的変数 |
このデータセットには 768 レコードが含まれ、合計 9 つの特徴があります。このデータセットを CSV ファイルとして Amazon Simple Storage Bucket (Amazon S3) に保存し、その CSV を Amazon S3 から Data Wrangler のフローに直接インポートしています。
ソリューション概要
この記事で達成することを以下の図にまとめます。

データサイエンティスト、医師、その他の医療領域の専門家は、糖尿病になりやすさを予測するためのデータとして、グルコースレベル、血圧、BMIや他の特徴量に関する患者データを提供します。Amazon S3 にあるデータセットを Data Wrangler にインポートし、探索的データ解析(EDA)、データプロファイリング、特徴量エンジニアリング、モデル構築と評価のための train と test へのデータセットの分割を実行します。
その後、Autopilot の新統合機能により、Data Wrangler のインターフェースから直接、素早くモデルを構築することができます。F-beta スコアが最も高いモデルに基づいて Autopilot のベストモデルを選択します。Autopilot がベストモデルを見つけた後に、ベストモデルのモデルアーチファクトを用いて、テスト(ホールドアウト)セットに対して SageMaker Batch Transform ジョブを実行して評価します。
医療専門家は、検証されたモデルに新しいデータを提供することで、患者が糖尿病になる可能性が高いかどうかの予測を得ることができます。これらの洞察により、医療専門家は早期に治療を開始し、脆弱な人々の健康と福祉を向上させることができます。また、医療専門家は、モデルの説明可能性、パフォーマンス、およびアーティファクトを完全に可視化できるため、Autopilot でモデルの詳細を参照しながら、モデルの予測を説明することができます。テストセットからのモデルの検証に加え、この可視化により、医療専門家はモデルの予測能力に対してより高い信頼性を得ることができます。
以下のハイレベルなステップを説明します。
- Amazon S3 からデータセットをインポートします。
- Data Wrangler で EDA とデータプロファイリングを実行します。
- 外れ値や欠損値を処理するための特徴量エンジニアリングを行います。
- データをトレーニングセットとテストセットに分割します。
- Autopilot でモデルを学習・構築します。
- SageMaker ノートブックを使って、ホールドアウトサンプルでモデルをテストします。
- 検証セットとテストセットのパフォーマンスを分析します。
前提条件
以下の前提条件のステップを完了してください。
- データセットを任意の S3 バケットにアップロードしてください。
- 必要な権限があることを確認します。詳細は Data Wrangler を始めようを参照してください。
- Data Wrangler を使用するように設定された SageMaker ドメインをセットアップします。手順については Amazon SageMaker ドメインの導入を参照してください。
Data Wrangler でデータセットをインポートする
Data Wrangler のデータフローを ML ワークフローに統合することで、データの前処理と特徴量エンジニアリングをシンプルかつ合理的に、ほとんどコーディングすることなく行うことができます。以下のステップを実施してください。
- Data Wrangler フローを新規に作成します。
Data Wrangler を初めて起動する場合、準備が完了するまでに数分待つ必要があります。
- Amazon S3 に保存されているデータセットを選択し、Data Wrangler にインポートします。
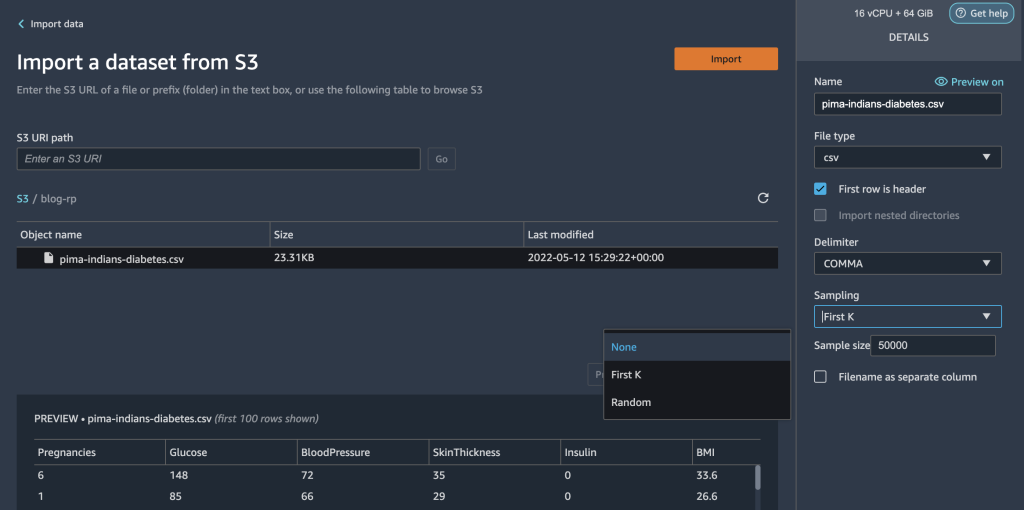
データセットをインポートすると、Data Wrangler の UI 内にデータフローの初期画面が表示されます。これでフロー図ができました。
- Data types の隣にあるプラス記号を選択し、Edit を選択して、Data Wrangler が自動的にデータ列のデータ型を正しく推測していることを確認します。

データ型が正しくない場合は、UI から簡単に修正することができます。複数のデータソースが存在する場合、それらを結合または連結することができます。
これで、分析を作成し、変換を追加することができます。
データインサイトレポートで探索的データ分析を実行する
探索的なデータ分析は、ML ワークフローの重要な部分です。Data Wrangler の新しいデータインサイトレポートを使用して、データのプロファイルと分布についてより深く理解することができます。このレポートには、要約統計、データ品質の警告、ターゲットカラムの洞察、クイックモデル、異常な行や重複した行に関する情報などが含まれています。
- Data types の横にあるプラス記号を選択し、Get data insights を選択します。
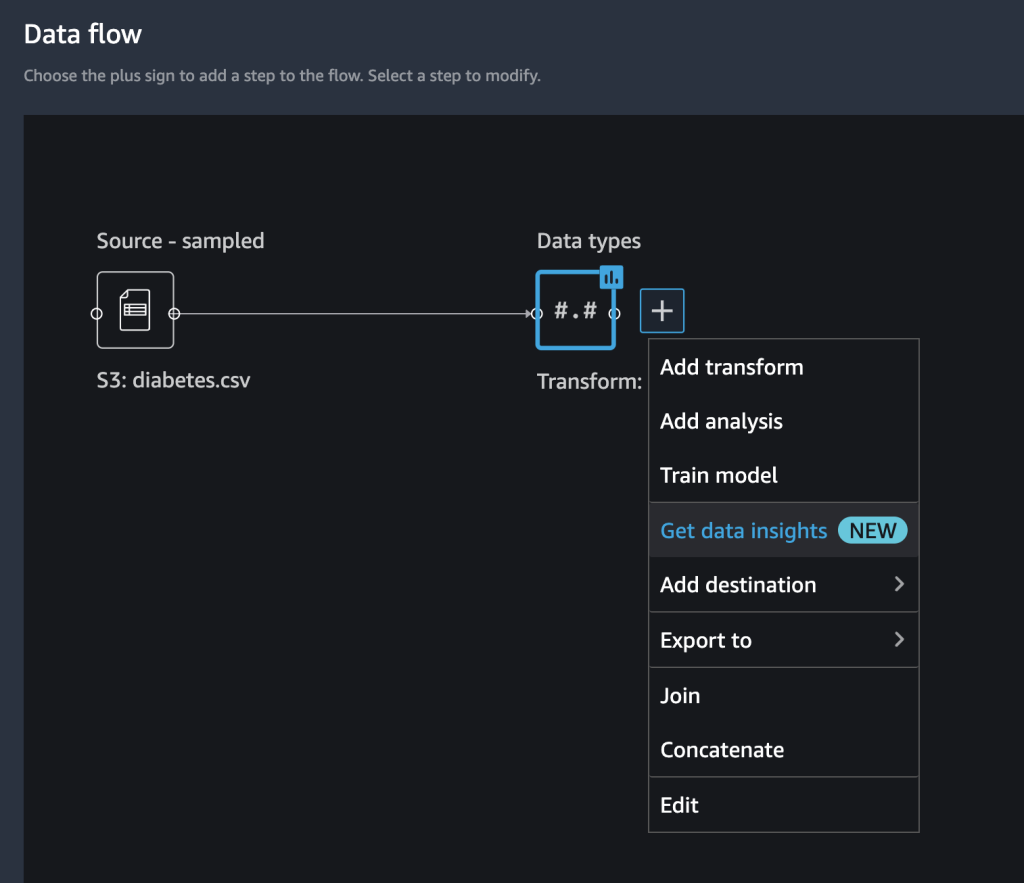
- Target column で Outcome を選択します。
- Problem type で Classification を選択します(オプション)。
- Create を選択します。

結果には、データセットの統計情報を含むサマリーデータが表示されます。
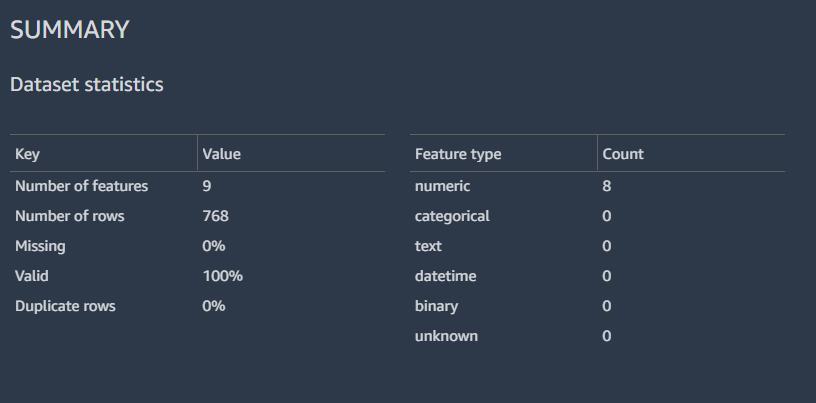
また、ヒストグラムによるラベル付き行の分布、クイックモデル機能で予測されるモデルの予測性能、およびフィーチャーサマリーテーブルを表示することができます。


本ブログではデータインサイトレポートの分析の詳細は割愛します。データインサイトレポートを使用してデータ準備のステップを加速する方法の詳細については、Accelerate data preparation with data quality and insights in Amazon SageMaker Data Wrangler を参照してください。
特徴量エンジニアリングの実行
入力カラムの分布を高レベルでプロファイリングおよび分析したので、データの品質を向上させるための最初の検討事項は、欠損値を処理することでしょう。
例えば、Insulin カラムのゼロ (0) は欠損値を表していることが分かっています。ゼロを NaN に置き換えるという推奨に従うことができます。しかし、よく調べてみると Glucose、BloodPressure、SkinThickness、BMI など他の列でも最小値が 0 であることがわかります。欠損値を処理する方法が必要ですが、ゼロを含む列が有効なデータであることを考慮する必要があります。これをどのように解決するか見てみましょう。
Feature Details セクションで、レポートは Insulin に対して Disguised missing value の警告を表示します。


Insulin 列のゼロは実際には欠損データであるため、Convert regex to missing transform を使用して、ゼロ値を空(欠損値)に変換します。
- Data types の隣にあるプラス記号を選択し Add transform を選択します。(訳者注:続いて Add steps を選択します)
- Search and edit を選択します。
- Transform で Convert regex to missing を選択します。
- Input columns で、
Insulin,Glucose,BloodPressure,SkinThickness,BMIの各列を選択します。 - Pattern には、
0を入力します。 - Preview と Add を選択して、このステップを保存します。
Insulin、Glucose、BloodPressure、SkinThickness、BMI の下にある 0 は、欠損値になっています。

Data Wrangler には、欠損値を修正するための他のオプションがいくつかあります。
Glucose列の中央値を近似的にインプットすることで、欠損値を処理します。

また、特徴量が同じスケールであることを確認したいと思います。より大きな数値範囲を含むからといって、ある特徴量に誤ってより多くの重みを与えたくはありません。そのために特徴量を正規化します。
- 新しい Process numeric 変換を追加し、Scale values を選択します。(訳者注:Data types の隣にあるプラス記号を選択し Add transform から操作できます)
- Scaler は Min-max scaler を選択します。
- Input columns で、
Pregnancies,BloodPressure,Glucose,SkinThickness,Insulin,BMI,Ageのカラムを選択します。 - Min を
0に、Max を1に設定します。(訳者注: Preview と Add を選択して、このステップを保存します。)
これにより、特徴量が 0 から 1 の間にあることを確認します。

これでいくつかの特徴ができたので、モデルを構築する前にデータセットを training と testing に分けます。
データをトレーニング用とテスト用に分ける
ML ワークフローのモデル構築フェーズでは、バッチ予測を実行することによってモデルの有効性をテストします。テストデータセットやホールドアウトデータセットを評価用に確保し、予測とグランドトゥルースを比較してモデルがどのように動作するかを確認することができます。一般的に、モデルの予測値の多くが true ラベルと一致すれば、そのモデルのパフォーマンスは高いと判断できます。
ここでは Data Wrangler を使い、テスト用のデータセットを分割します。今回使用するデータセットは比較的サイズが小さいため、 90% のデータセットをトレーニング用に保持します。残りの 10% はテストデータセットとして使用します。このデータセットは、この記事の後半で Autopilot モデルを検証するために使用します。
データを分割するため Split data 変換を選択し、手法として Randomized split を選択します。割合は、トレーニングでは 0.9 、テストでは 0.1 としています。(訳者注:Data types の隣にあるプラス記号を選択し Add transform から操作できます)

データ変換と特徴量エンジニアリングのステップが完了し、モデルをトレーニングする準備が整いました。(訳者注: Preview と Add を選択して、このステップを保存します。)
モデルの学習と検証
Data Wrangler と Autopilot の統合により Data Wrangler のデータフロー UI から直接モデルを学習させることができます。
- Dataset の隣にあるプラス記号を選択し Train model を選択します。
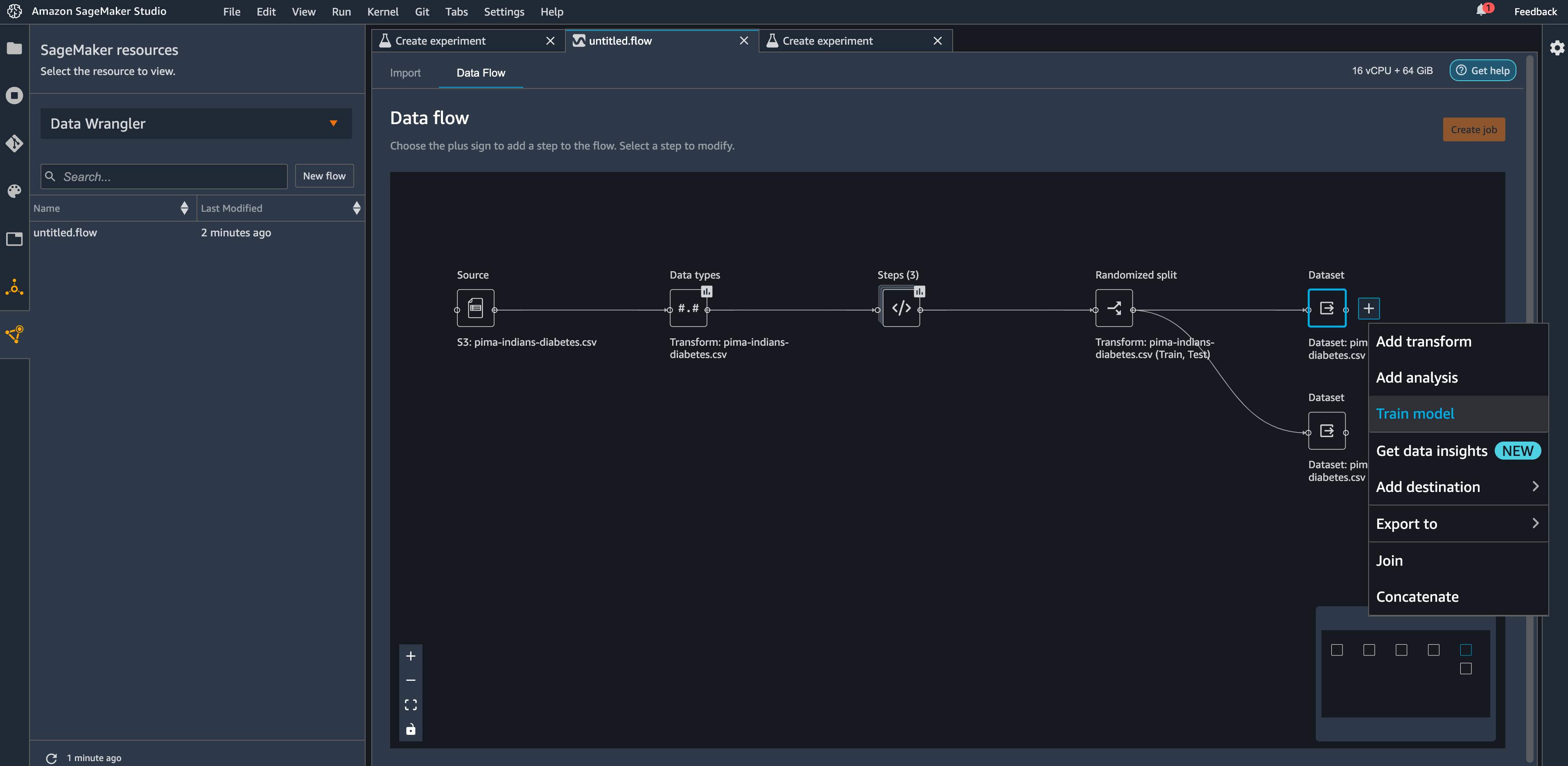
- Amazon S3 location には、SageMaker がデータをエクスポートする Amazon S3 の場所を指定します。
Autopilot はこのパスを利用して自動的にモデルを学習させるため、Data Wrangler フローの出力場所を設定した後に、再度 Autopilot の学習データの入力場所を設定するという手間が省けます。これにより、よりシームレスなエクスペリエンスを実現します。
- Export and train を選択し Autopilot によるモデル構築を開始します。

Autopilot は自動的にトレーニングデータの入力と出力の場所を選択します。ターゲット列を指定し Create Experiment をクリックするだけで、モデルをトレーニングすることができます。

ホールドアウトサンプルでモデルをテストする
Autopilot が実験を完了すると、学習結果を表示し、最適なモデルを探索することができます。

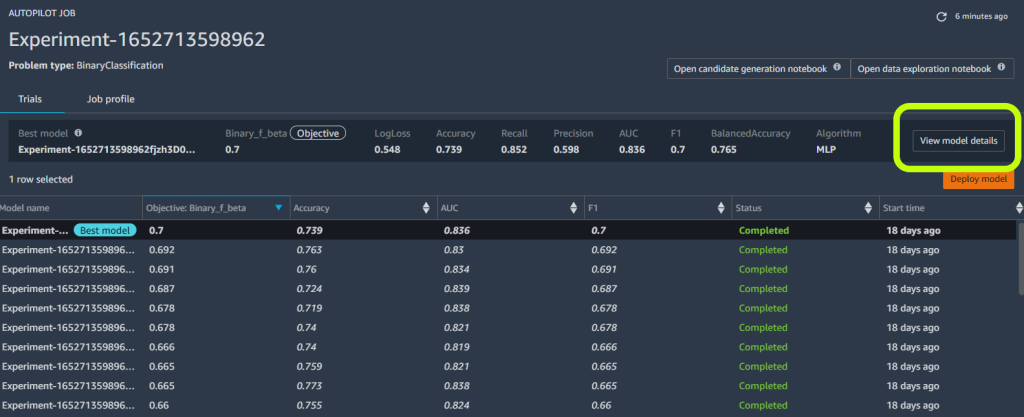
- 望ましいモデルの View model details を選択し、モデル詳細ページの Performance タブを選択します。

Performance タブには、混同行列、Area Under the precision/recall Curve (AUCPR) 、Receiver Operating Characteristic Curve (ROC 曲線) など、いくつかの指標でテストされたモデルの結果が表示されます。これらは、モデルの全体的な検証性能を示しますが、モデルがうまく汎化されているかどうかはわかりません。ある個人が糖尿病になるかどうかをモデルがどれだけ正確に予測するかを見るためには、未知のテストデータで評価を実行する必要があります。
モデルが十分に汎化されているかを確認するために、テストサンプルを独立サンプリングに設定します。これは Data Wrangler のフロー UI で行えます。
- Dataset の隣にあるプラス記号を選択し Export to を選択し Amazon S3 を選択します。
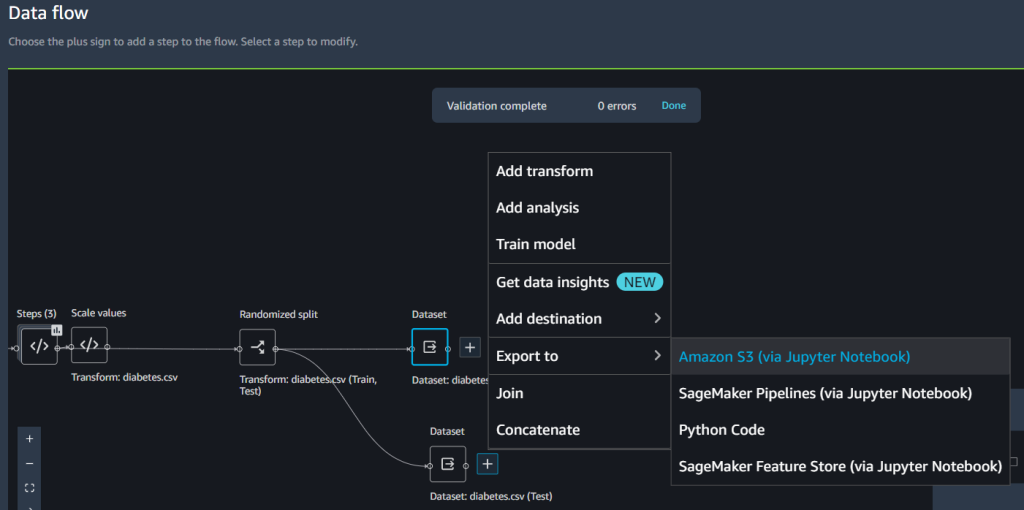
- Amazon S3 のパスを指定します。
このパスは、次節の検証のためのバッチ推論を実行する際に参照します。
- SageMaker のノートブックを新規作成し、ホールドアウトサンプルに対してバッチ推論を行い、テスト性能を評価します。以下の GitHub レポジトリを参考に、検証のためのバッチ推論を実行するサンプルノートブックを作成します。(訳者注:ノートブックは us-east-2 リージョンを利用するように記述されています。必要に応じて書き換えてください)
検証用とテストセットの性能の分析
バッチ変換が完了したら、ホールドアウトデータセットの実際の結果と予測結果を比較するために、混同行列を作成します。
その結果、23 の真陽性と 33 の真陰性が確認されました。この場合、真陽性とは、モデルがある個人を糖尿病であると正しく予測したことを意味します。一方、真陰性は、モデルがある個人を糖尿病でないと正しく予測することを意味します。

このケースでは、適合率 (Precision) と再現率 (Recall) が重要な指標となります。Precision は、本質的に糖尿病であると予測されたすべての個人を測定し、何人が本当に糖尿病であるかを測ります。それに対して Recall は、実際に糖尿病であるすべての個人を測定するのに役立ちます。例えば、最初の段階の治療が糖尿病でない人に効果がない場合(これは偽陽性で、実際には糖尿病でないのに糖尿病であるとラベル付けされた人)、できる限り多くの人を治療したいので、高い精度のモデルを使用したいと思うかもしれません。
また、結果を評価するために ROC 曲線下面積 (AUC) グラフをプロットします。AUC が高いモデルほどクラス間の識別に優れています。この場合、モデルは糖尿病の患者とそうでない患者をどれだけ区別できるかを示しています。

まとめ
この記事では Data Wrangler と Autopilot を使用して、データ処理、特徴量エンジニアリング、モデル構築を統合する方法を紹介しました。Data Wrangler のユーザーインターフェースから直接 Autopilot で簡単にモデルをトレーニング、チューニングできることを紹介しました。この統合機能により、特徴量エンジニアリングが完了した後、コードを書かずに素早くモデルを構築することができるようになりました。その後、Autopilot の最適なモデルを参照し SageMaker Python SDK で AutoML クラスを使用してバッチ予測を実行しました。
Data Wrangler や Autopilot のようなローコードソリューションや AutoML ソリューションは、ロバストな ML モデルを構築するための深いコーディング知識は必要ありません。Data Wrangler を利用し、SageMaker Autopilot を使った ML モデルの構築がいかに簡単であるかをお試しください。
著者について
Peter Chung
Peter Chung は AWS のソリューションアーキテクトで、お客様がデータからインサイトを発見することを支援することに情熱を注いでいます。公共と民間の両方で、組織がデータ駆動型の意思決定を行うためのソリューションを構築してきました。AWS の全認定資格と 2 つの GCP 認定資格を保有しています。趣味は、コーヒー、料理、体を動かすこと、家族と過ごすことです。
Pradeep Reddy
Pradeep Reddy は SageMaker Low/No Code ML チームのシニアプロダクトマネージャで SageMaker Autopilot や SageMaker Automatic Model Tuner などがこれにあたります。仕事以外では、読書、ランニング、ラズベリーパイなどの手のひらサイズのコンピュータやその他のホームオートメーション技術に熱中することを楽しんでいます。
Arunprasath Shankar
Arunprasath Shankar は、AWS の人工知能および機械学習 (AI/ML) スペシャリスト ソリューションアーキテクトで、グローバルな顧客がクラウドで AI ソリューションを効果的かつ効率的に拡張できるよう支援しています。趣味は SF 映画鑑賞とクラシック音楽鑑賞です。
Srujan Gopu
Srujan Gopu は SageMaker Low Code/No Code ML のシニアフロントエンドエンジニアとして Autopilot および Canvas 製品のお客様を支援しています。コーディング以外の時間は、愛犬のマックスとランニングをしたり、オーディオブックを聴いたり VR ゲーム開発を楽しんでいます。
翻訳は Solutions Architect 片山洋平 が担当しました。原文はこちらです。
からの記事と詳細 ( Amazon SageMaker Data Wrangler と Amazon SageMaker Autopilot によるデータ準備とモデルトレーニングの一元化 | Amazon Web Services - amazon.com )
https://ift.tt/vH8BruG
No comments:
Post a Comment